Data-Science-Portfolio
Includes resume, one-pagers of work done, and examples of programming and data science projects
View the Project on GitHub RicardoFrankBarrera/Data-Science-Portfolio
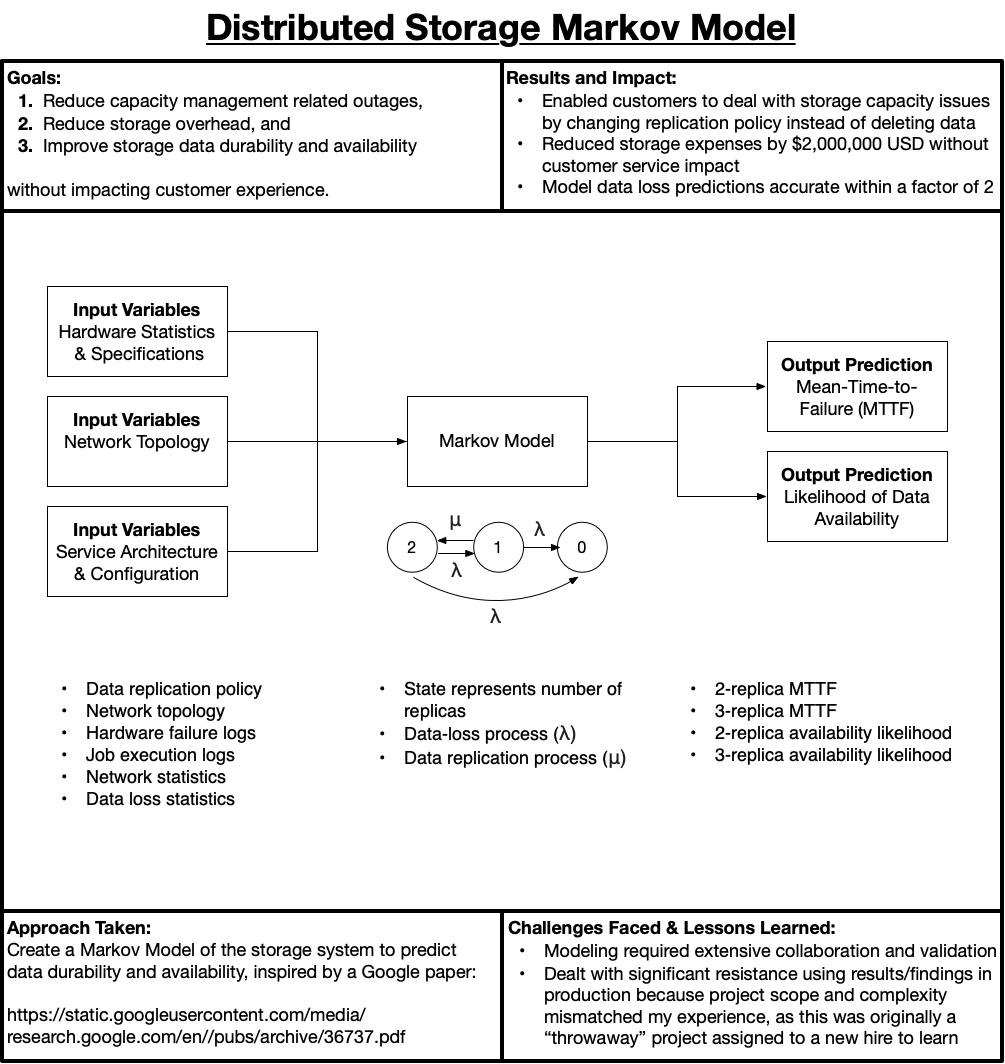
@Microsoft: Modeling Cosmos Store’s Data Durability and Availability
Business Context
This project was a LOT of fun and was my first project after joining the Big Data team at Microsoft as a Program Manager. I am pretty sure my manager intended it to be a throwaway project to help me learn, but we got some pretty good results from it.
For background, Microsoft’s Big Data system is named Cosmos (click for the whitepaper). As of 2011, Cosmos was storing approximately an Exabyte of data and had an operating expense budget of about $100,000,000 running several data centers to power many of Microsoft’s services (e.g., Bing). Therefore, minor improvements to storage efficiency without impacting customer experience made a large impact on Microsoft’s business.
My task was to recreate the same study done at Google (click for the whitepaper) for our system. In short, Google aggregated a lot of system log data, analyzed it, and pushed it through a Markov Model to predict data durability (how often data would be lost) and availability (how often data was accessible).
Modeling Process
The Markov Model’s assumptions don’t fit reality because a Markov Model assumes event independence, but we know that hardware fails are correlated; a machine that has failed before is more likely to fail again. I believe there is a relevant quote for every occasion including this one, courtesy of George Box: “All models are wrong, but some are useful.” Despite being wrong, this model turned out to be very useful.
Creating this model proved to be challenging for various reasons:
- Identifying what data was needed, where it was located, and how to access it was difficult because there were hundreds of services running in a data center logging various events owned by several different teams (I got lots of exercise running between offices chatting with domain experts and service owners)
- Interpreting the data correctly was an issue because event logs sometimes had ambiguous meaning for certain events, were incomplete / lossy, or were duplicated
- Modifying the Markov Model for our system was non-trivial because our replication policies and configurations including geo-replicated data, meaning my Markov Model was more of a 2-D matrix than a 1-D array
- Scalably processing the data (10+ Terabytes per year), computing all necessary statistics, and validating model accuracy was challenging because data-loss was an infrequent event; in fact, most data loss was software related or due to human error as opposed to hardware failure, outside of the model’s scope
Closing Thoughts
The benefits of effectively modeling the system for this narrow goal were surprisingly broad. This fairly simple model allowed us to make key business decisions and optimizations intelligently. For example, we used the model to:
- Optimize storage replication policies based upon customer needs to reduce cost of service by 10-15%,
- Reduce customer service outages due to capacity management issues,
- Advise on network topologies and bandwidth requirements for data centers,
- Evaluate the pros/cons of other replication schemes (e.g., Erasure Encoding)
It’s impressive how many unintended benefits and use-cases come up from simple models.