Data-Science-Portfolio
Includes resume, one-pagers of work done, and examples of programming and data science projects
View the Project on GitHub RicardoFrankBarrera/Data-Science-Portfolio
@Accolade: Recommendation System for Health Assistants
This project is a good example of what it takes to develop an intelligent service from the ground up. I had the fortunate privilege of defining, driving, and implementing the Data Science team’s first production service, a Health Assistant Recommendation System.
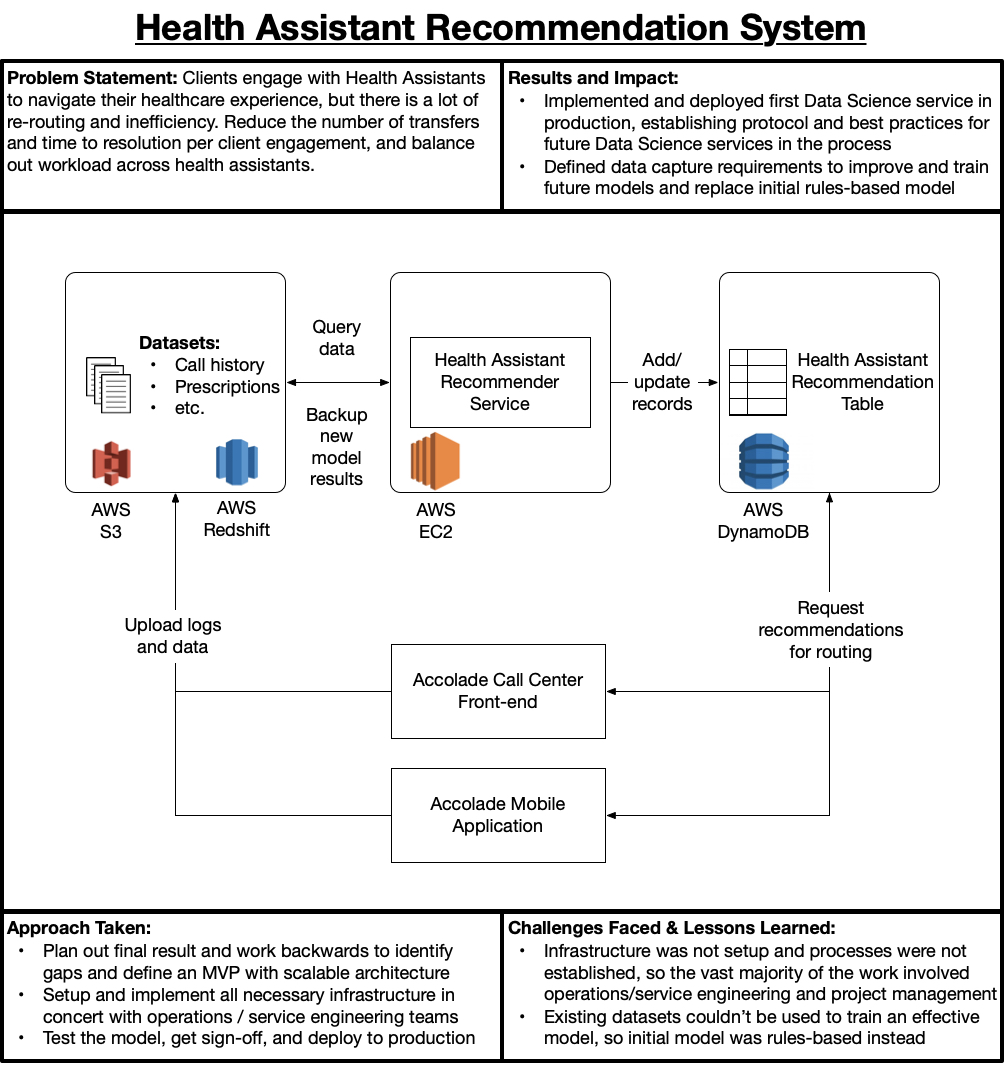
Business Context
Accolade’s core business value-add comes from the engagement and relationship between Clients and Health Assistants. A Health Assistant efficiently and effectively navigates a Client through their healthcare experience, saving time and money while improving outcomes. As such, it is critical that the right Health Assistant be paired with the Client, as different Health Assistants have different expertise (e.g., some are Benefits experts, others are Clinicians, etc.). This Recommendation System’s main goals were to improve Client outcomes while improving operating efficiency on Accolade’s side. The metrics of choice to measure success for this were low-level operations metrics (e.g., Call Duration, Call Re-Routes per Engagement) and high-level business metrics (e.g., Net Promoter Score).
Service Design Challenges
Bringing this service to life was particularly challenging for many reasons, mainly:
- Most of Accolade’s infrastructure was being re-architected to support future scenarios (i.e., nobody knows what plugs into where anymore),
- Best-practices and policies for developing and deploying services were undefined in the new architecture,
- Much of the existing Data Ecosystem was useless, so an intelligent system would need to be bootstrapped without data
How does one bootstrap an intelligent service without data? You operate with rules/heuristics coded in the initial version, and define telemetry to record and train an intelligent model with after-the-fact. So, in this case the initial version was simply a load-balancer that re-assigned Health Assistants to Clients based upon personnel load, and the subsequent data would become the foundation for an intelligent service using some Machine Learning techniques (e.g., Random Forest, Collaborative-Filtering).
In this case, 80% to 90% of the work for the initial model was simply getting the plumbing in place: setting up roles and permissions for services, service logging and alerting, configuring the service to log the correct data with the correct schema for future iterations, and so on. In the end, the initial model was a simple EC2 service that would run once per day to update Health Assistant assignments in a DynamoDB table.
Closing Thoughts
I left Accolade shortly after deploying this service so I didn’t see further iterations beyond the initial model. At the time, the plan was to evaluate the existing model’s performance against key metrics (e.g., Call Duration) alongside new models, and switch over to a new intelligent model once a statistically significant improvement was achieved. It is essential to use and conduct statistical testing correctly because small sample sizes or heterogenous populations can be misleading. A seemingly better model may actually be worse. The statistical test is the compass to determine whether we’re heading in the right direction.